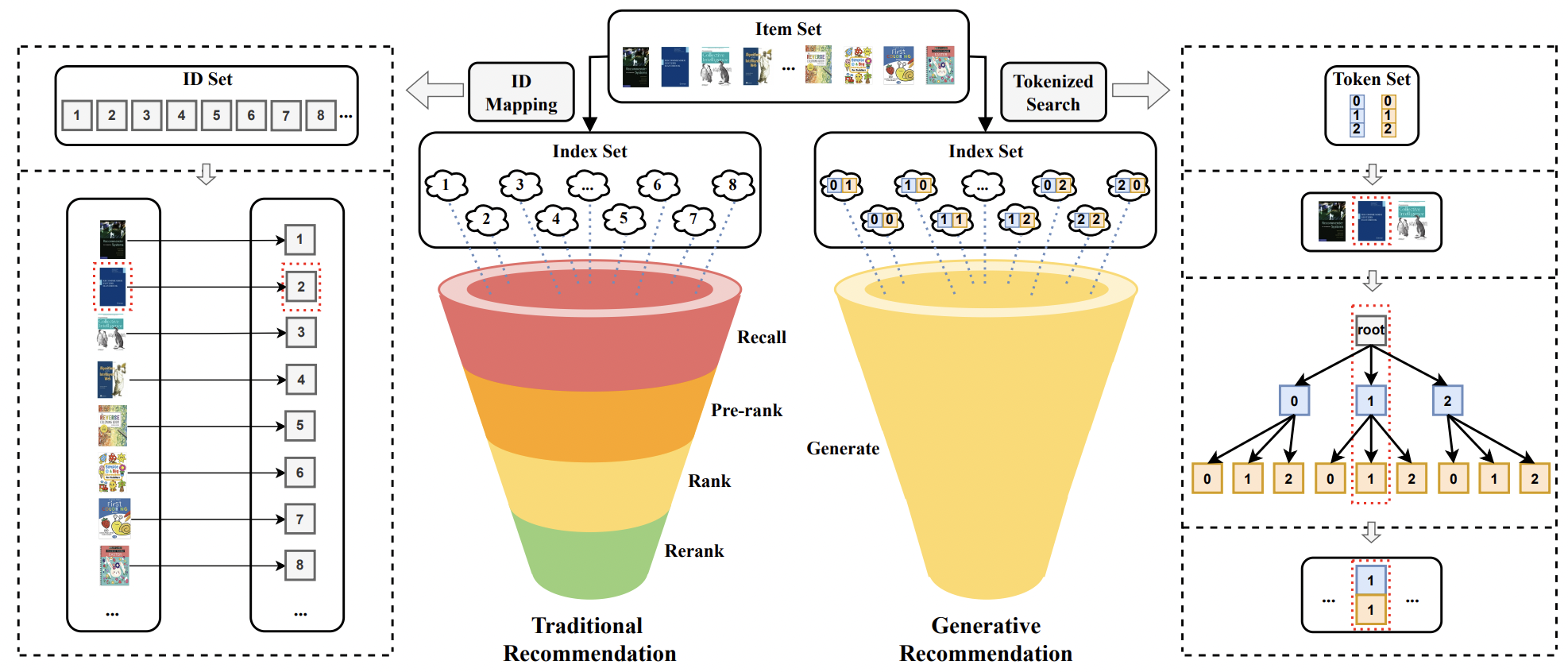
Introduction
We introduce datasets that facilitate LLM-based recommendation models. This is particularly important for data-centric machine learning such as LLM-based recommender systems, since the pre-training of LLMs largely determines the ability and utility of LLM-based recommendation.
Large language models for recommender system
We organize and introduce recent LLM-based recommendation models, their relationships, various pre-training, fine-tuning and prompting strategies of LLM-based recommendation models, and possible directions for future improvements.
Trustworthy Large language models for recommender system
We introduce research on the trustworthiness on LLM-based recommender models, including hallucination, fairness, transparency, robustness, and controllability.
We introduce existing open-source models and platforms to facilitate LLM-based recommendation research, including both LLM backbones such as T5 and LLaMA, and LLM-based recommendation platforms such as OpenP5.
Summary
Finally, we introduce existing industrial LLM systems that support recommender functionality and their advantages and problems to improve. Examples include ChatGPT, Microsoft Bing and Google Bard.
Wenyue Hua is a PhD student in the Department of Computer Science at Rutgers University under the supervision of Prof. Yongfeng Zhang. Her research interest focuses on the intersection of Natural Language Processing and Recommender Systems. Her current research focuses on LLM and its application on recommendation. In the previous she did her BA in Linguistics and BS in Mathematics at UCLA. Her research appears on SIGIR, TACL, EMNLP, ICLR, etc. and she is actively serving as a reviewer for conferences such as RecSys, WWW, SIGIR, ACL, and EMNLP.
Lei Li is a post-doc at the Department of Computer Science, Hong Kong Baptist University (HKBU), and a visiting researcher at the Department of Computer Science, Rutgers University. He has been working on large pre-trained language models for recommender systems. He did PhD at the same department at HKBU and worked on large language models for explainable recommendation. His research appears on SIGIR, WWW, ACL, CIKM, TOIS, etc. and he regularly serves as PC member or reviewer for conferences and journals such as WWW, RecSys, TKDE, TOIS, etc.
Shuyuan Xu is a PhD student in the Department of Computer Science at Rutgers University supervised by Prof. Yongfeng Zhang. His research interest lies in the intersection of Machine Learning and Information Retrieval. His current research focuses on large language models for recommendation. He has published on RecSys, SIGIR, WWW, CIKM, ICTIR, TORS, IJCAI, WSDM, etc. and he is actively serving as reviewer for conferences or journals such as AAAI, SIGIR, WWW, CIKM, RecSys, KDD, ACM TOIS, ACM TORS, IEEE TKDE. He co-organized the Tutorial on Advances in Simulation Technology for Web Applications at WWW 2023.
Li Chen is Associate Head (Research) and Professor at the Department of Computer Science, Hong Kong Baptist University. Her research focus is on developing trustworthy and responsible data-driven personalization systems, which integrate research in artificial intelligence, recommender systems, user modeling, and user behavior analytics for the application in various domains including social media, e-commerce, online education, and mental health. She has authored and co-authored over 100 publications, most of which appear in high-impact journals (such as IJHCS, TOCHI, UMUAI, TIST, TIIS, KNOSYS, Behavior & Information Technology, AI Magazine, and IEEE Intelligent Systems), and key conferences in the areas of data mining (SIGKDD, SDM), artificial intelligence (IJCAI, AAAI), recommender systems (ACM RecSys), user modeling (UMAP), and intelligent user interfaces (CHI, IUI, Interact). She is now an ACM senior member, co-editor-in-chief of ACM Transactions on Recommender Systems (TORS), editorial board member of User Modeling and User-Adapted Interaction Journal (UMUAI), and associate editor of ACM Transactions on Interactive Intelligent Systems (TiiS). She has also been serving in a number of journals and conferences as guest editor, general co-chair, program co-chair, and senior PC member.
Yongfeng Zhang is an Assistant Professor in the Department of Computer Science at Rutgers University. His research interest is in Information Retrieval, Recommender Systems, Machine Learning, Data Mining and Natural Language Processing. In the previous he was a postdoc in the Center for Intelligent Information Retrieval (CIIR) at UMass Amherst, and did his PhD and BE in Computer Science at Tsinghua University, with a BS in Economics at Peking Univeristy. He is a Siebel Scholar of the class 2015. He has been consistently working on recommender system research including explainable recommendation, fairness-aware recommendation, conversational recommendation, and large language models for recommendation. His research appears on related conferences such as RecSys, SIGIR, WWW, CIKM, WSDM, KDD, TOIS, TORS, etc. He serves as Associate Editor for ACM Transactions on Information Systems (TOIS) and ACM Transactions on Recommender Systems (TORS) and senior PC member or area chair for RecSys, SIGIR, WWW, KDD, CIKM, AAAI, etc. He has co-organized Tutorial on Explainable Recommendation and Search (WWW, SIGIR, ICTIR), Tutorial on Conversational Recommendation Systems (RecSys, WSDM, IUI), and Tutorial on Fairness of Machine Learning in Recommender Systems (SIGIR, CIKM).